Scraping for Cache, Or: It’s Not Piracy if You Left It Out in the Open
Proudly included in the Spring 2016 edition of 2600 magazine!

Proudly included in the Spring 2016 edition of 2600 magazine!
As a student, I love to have digital copies of my textbooks available. Ease of reference, portability, and minimal back strain are 3 reasons why finding digital copies of my books are hugely important to me. Therefore, I’m understandably annoyed when textbooks, especially ones that are several years old, can’t be found online, or are available in online stores at exorbitant prices. Absolute madness!
A recent example of this heinous lack of electronic books would be my APUSH textbook. It isn’t terribly old, in fact, it was published in 2012, and an online edition is available from McGraw Hill. In theory, an online edition should mean the end of my accessibility problem (and back pain), however, in order to access the online edition, I’d an access code from my school, something that they had not and could not provide to me. With all legitimate means of digital access exhausted, I would have to resort to other methods of enabling my laziness…
Enter Google.
As Google’s web spiders crawl the web, they not only index web pages, but they also cache copies of pages, usually for a month or so, during which Google will host its own copy of the resource. In practice, this means that there’s often a good chance that content on the web that has been deleted by a site owner is retrievable, so long as it has been indexed by Google. In fact, there are several organizations that exist to do exactly this sort of thing, most notably Archive.org, though Google is usually better about getting into the smaller cracks and crevices of the internet where my books are more likely to be stored.
Research.
To start off my search, I searched for exact strings taken out of my textbook, which usually leads to a PDF scan of a section that’s clear enough for google to run OCR. What I found, however, was something much, much better: Google had indexed pages directly from McGraw Hill’s development servers, with cached copies that spanned the entire book!
And not only my APUSH textbook, but many, many others as well:
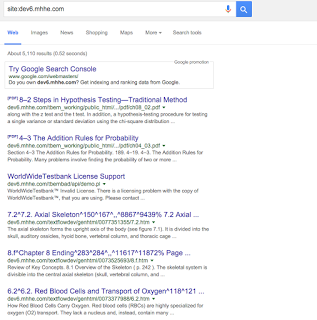
A few quick observations for each URL led me to a way to programmatically download the book:
- Each URL followed the same format, http://dev6.mhhe.com/textflowdev/genhtml//..htm
- Cached versions of webpages could be easily retrieved from Google with the following URI format: https://webcache.googleusercontent.com/search?q=cache:<full URL of resource>.
- My book has no more than 32 chapters, with no more than 7 sections per chapter, which means there are 224 pages to potentially retrieve in total.
The Script.
That said, I whipped up the following script, which, though simple, was able to completely retrieve my textbook from Google’s cache and compile all of the downloaded HTML files into a single PDF:
echo "Downloading APUSH book..."
# Initialize total downloaded count.
DLT=0
echo "Creating downloads directory (./apush-dl)"
# Create downloads directory and redirect stderr to /dev/null (in case the directory already exists).
mkdir ./apush-dl/ 2>/dev/null
# There are 32 chapters.
for CHAP in {1..32}; do
# There are never more than 7 sections per chapter.
for SECT in {1..7}; do
# We want to test whether the file is available first before attempting to download, so we grab the HTTP response code first.
# We also randomize the useragent somewhat in order to appear less like a script.
RESCODE="$(curl -o /dev/null --silent --head --write-out '%{http_code}' \
"https://webcache.googleusercontent.com/search?q=cache:dev6.mhhe.com/textflowdev/genhtml/0077379578/$CHAP.$SECT.htm" \
-A "Mozilla/5.0 (Linux; U; Android 4.2.2; en-us; AppleWebKit/$SECT$CHAP.$CHAP (KHTML, like Gecko) Version/$CHAP.$SECT$SECT Mobile Safari/$SECT$CHAP$SECT.$CHAP$CHAP $CHAP-$SECT")"
echo "Downloading Chapter $CHAP Section $SECT:"
# Make sure we get a 200 response before downloading.
if [[ $RESCODE == "200" ]]; then
# And download the page (once again, ensuring that the UA appears somewhat unqiue).
curl --progress-bar -o "./apush-dl/$CHAP.$SECT.html" \
"https://webcache.googleusercontent.com/search?q=cache:dev6.mhhe.com/textflowdev/genhtml/0077379578/$CHAP.$SECT.htm" \
-A "Mozilla/5.0 (Linux; U; Android 4.2.2; en-us; AppleWebKit/$SECT.$CHAP (KHTML, like Gecko) Version/$CHAP.$SECT$SECT Mobile Safari/$SECT$CHAP$SECT.$CHAP$CHAP $CHAP-$SECT"
# Increment total downloaded by 1.
DLT=$(($DLT+1))
else
# Otherwise, display an error. 302 usually means that Google has begin blocking requests.
echo "Got an error! Code: $RESCODE"
fi
done
done
# Delete any files containing the string "Error 404", which would be unique to Google's error pages.
echo "Deleting 404 files..."
find ./apush-dl/ -type f -exec egrep -Il 'Error 404' {} \; | xargs rm -v -f
# Append CSS to each file to hide the annoying Google Cache info banner.
echo "Hiding cache info banner..."
for file in ./apush-dl/*.html; do echo "<style>#google-cache-hdr{display:none!important}</style>">>"$file"; done
echo -e "Downloaded $DLT pages in total. \n"
# Compile all HTML files into a single PDF for ease of use and transport.
# Load no images, as the src files are not available from the original dev servers.
# This depends on the wonderful wkhtmltopdf utility, from http://wkhtmltopdf.org/.
read -p "Create PDF of book? (requires wkhtmltopdf) " -n 1 -r
echo -e "\n"
if [[ $REPLY =~ ^[Yy]$ ]]
then
echo "Compiling PDF..."
wkhtmltopdf --no-images `find ./apush-dl/* | sort -n | grep html` apush_book.pdf
fi
echo "All done!"
Which left me with a complete, text-only copy of my book! Excellent!
*Note: The book has since been removed from Google’s cache, rendering the script unusable in its current state.
So, what have we learned?
As a company dealing in an industry where piracy is a major concern, McGraw Hill should take extra precaution to ensure that all of its content, especially content that they’re keen to monetize, is kept strictly under their control. This means securing any channel where this content could be exposed, which, in this case, was their dev servers. Even when a resource is deleted from a site, there are usually cached copies available somewhere, and once it’s out on the web, it’s out of your control.
Another thing that webmasters can gather from this is that all web content you host, even content hidden under several layers of obfuscation, may as well be considered wide open to the web unless some kind of authentication is implemented. If it exists on your server, accessible to anyone, then anyone will access it.
With the above in mind, I hope that you’ve learned something about keeping your content, and channels that lead to your content, in check and under your control.
Happy hacking!
Originally published at blog.ctis.me on April 10, 2016.